문과도 바로 이해하는 ChatGPT 학습 방법과 작동 원리
글ㅣ최기원 엔지니어
문과도 바로 이해하는 ChatGPT 학습 방법과 작동 원리
일자
상시
유형
아티클태그
이 아티클은 <쉽게 읽는 AI> 시리즈의 1화입니다.

본 아티클은 ‘ChatGPT’ 학습 방법에 대해 아주 쉽게 설명하는 글입니다. ChatGPT의 정확한 학습 방법이 공개되지 않았기 때문에, ChatGPT의 전신으로 여겨지는 ‘InstructGPT’를 학습한 방법을 소개합니다.
본격적인 설명에 들어가기 앞서 아티클에서 등장하는 AI 용어와 학습 방법을 눈에 익히고 넘어가겠습니다. 먼저 용어로는 ‘GPT-3, InstructGPT, SFT 모델, 리워드 모델’이 있으며 이는 모두 ‘GPT-3’에서 시작해 각기 다른 학습을 거친 버전의 모델입니다.
본격적인 설명에 들어가기 앞서 아티클에서 등장하는 AI 용어와 학습 방법을 눈에 익히고 넘어가겠습니다. 먼저 용어로는 ‘GPT-3, InstructGPT, SFT 모델, 리워드 모델’이 있으며 이는 모두 ‘GPT-3’에서 시작해 각기 다른 학습을 거친 버전의 모델입니다.
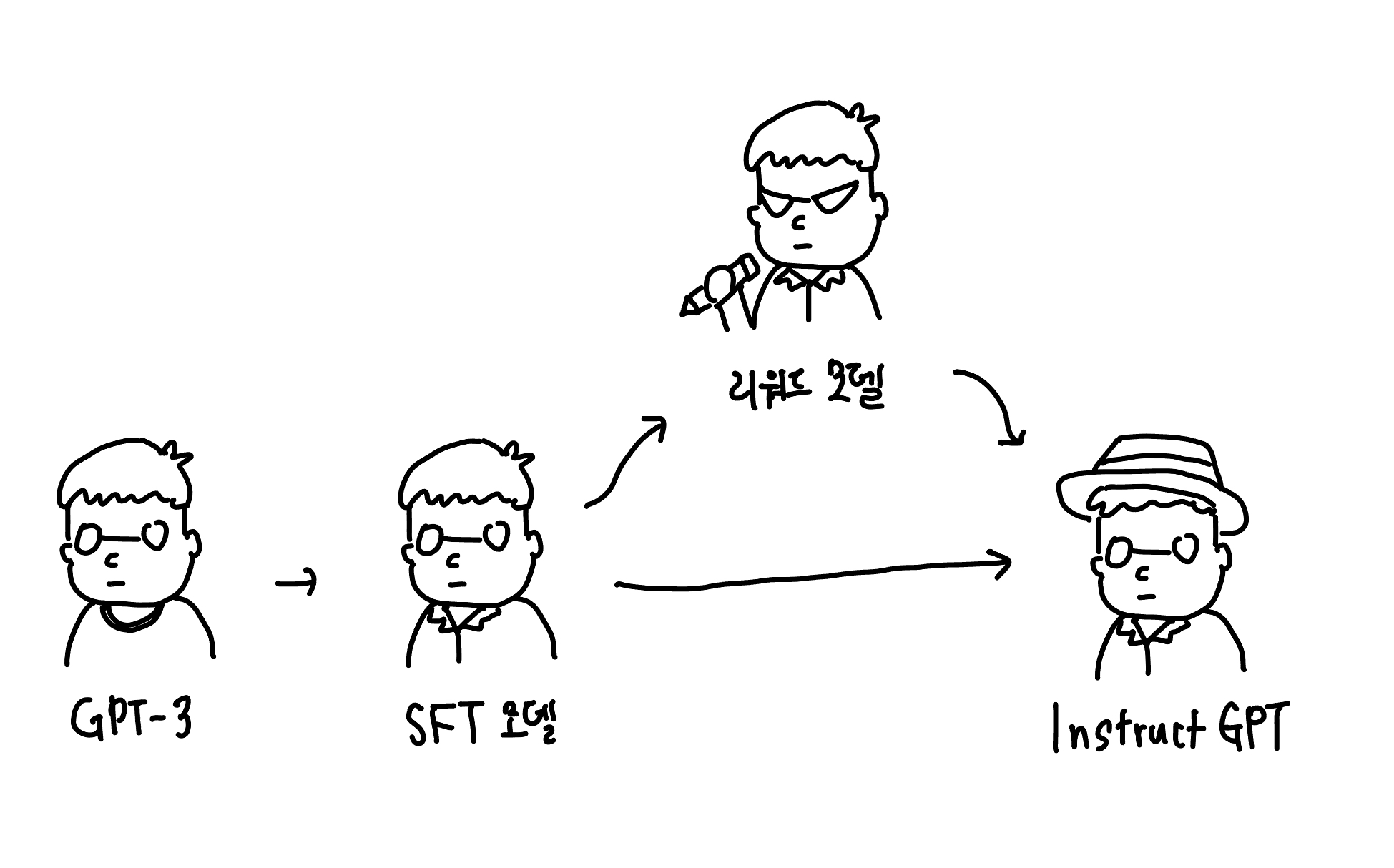
다음으로 학습 방법은 사전 학습(Pre-training), 미세조정(Fine-tuning), ‘RLHF’가 있습니다. 이들은 InstructGPT를 만들기 위해 거쳐야 하는 학습 과정입니다. 용어와 방법의 자세한 설명은 본문에서 이어집니다.

✅ 다음 단어를 예측하는 GPT-3의 등장
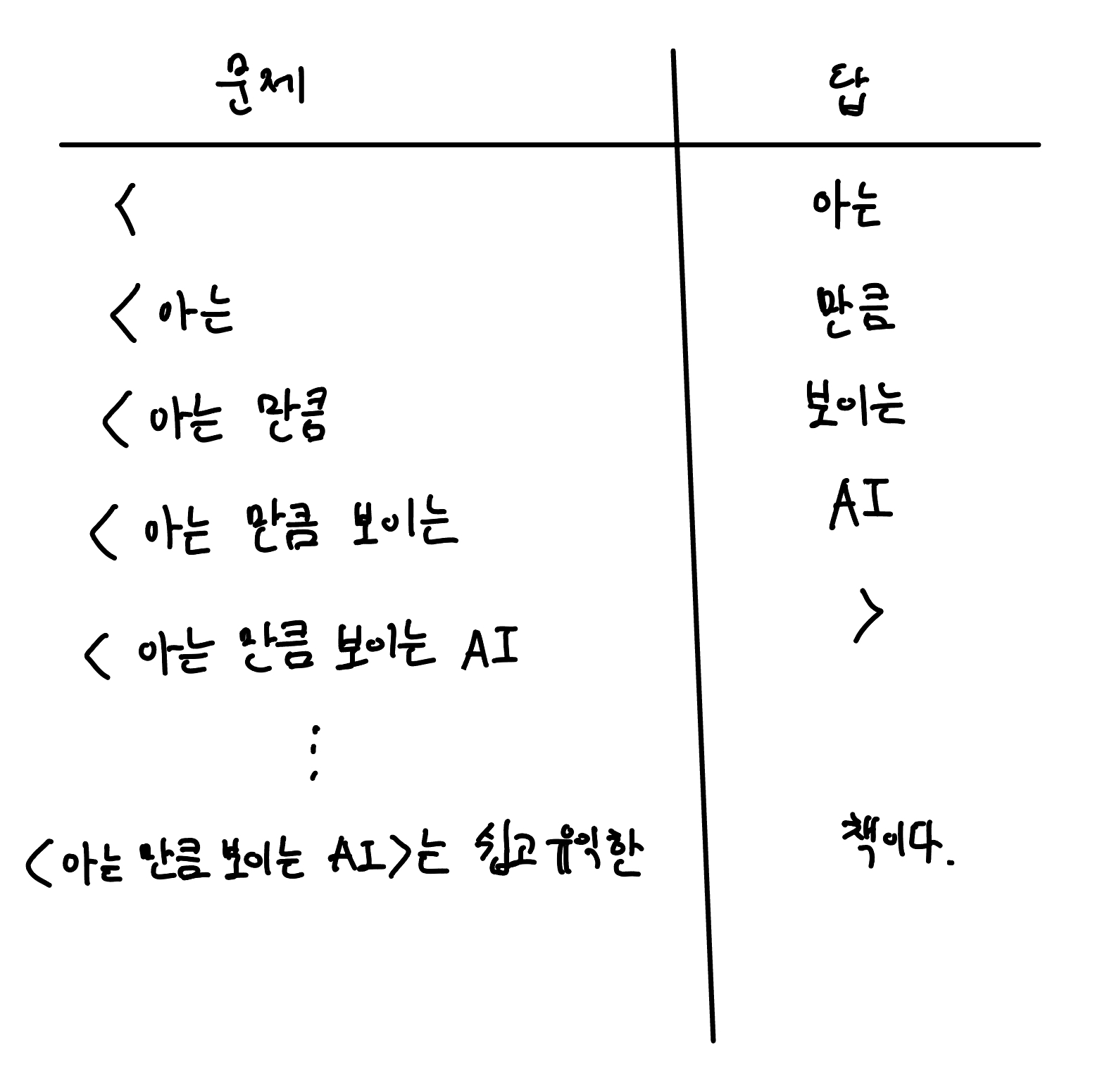
GPT-3는 ‘오픈AI’에서 선보인 모델이며 ‘다음 단어 예측’하는 학습을 많이 한 모델입니다. 웹 상에 있는 수많은 문서에 있는 문장을 가지고 다음 단어를 예측하는 학습을 한 것이에요. 예를 들어 문서에 ‘<아는 만큼 보이는 AI>는 쉽고 유익한 책이다.’라는 문장이 있으면, 이 문장을 가지고 다음과 같은 예측을 수행합니다. 문장의 앞부분이 주어졌을 때, 바로 다음에 어떤 단어가 나올지 예측하는 것이죠.
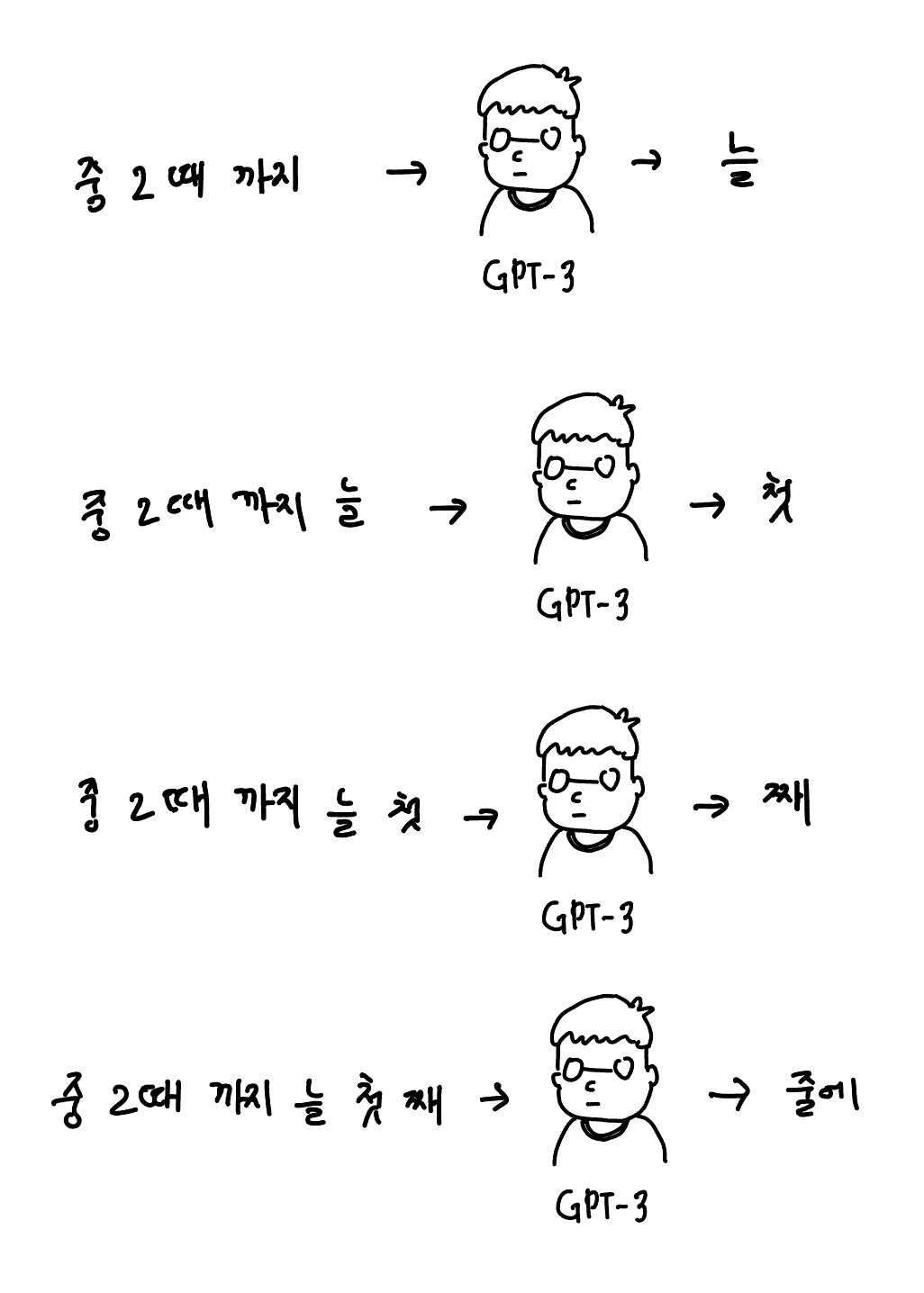
앞선 학습을 굉장히 많이 시키면 GPT-3는 비로소 ‘다음 단어를 잘 예측하는 엔진’ 역할을 수행할 수 있게 됩니다. 다음 단어를 잘 예측하는 엔진이 있으면 꽤 많은 일을 할 수 있습니다. 기본적으로 미완성 상태인 문장에 엔진을 여러 번 사용해 문장을 완성할 수 있죠.
또한, 문장을 완성시키는 능력이 있으면 사람이 언어를 사용해 할 수 있는 대부분의 일을 할 수 있습니다. 예를 들면 GPT-3는 객관식 문제를 해결할 수 있고 대화도 주고받을 수 있습니다. (아래 예시에서 밑줄 친 부분은 GPT-3가 생성한 부분입니다.)
질문: 10살짜리 남자 아이가 차가운 공기와 알레르기로 인한 지속적인 호흡 곤란과 기침을 겪고 있다.
여러 테스트를 해본 결과 이 환자는 폐쇄성 질환으로 판명되어 약을 처방 받았다.
다음 수용체 중 이 약이 작용할 가능성이 높은 수용체는 무엇인가?
A) 무스카린성아세틸콜린수용체
B) G 단백질 연결 수용체
C) Era
D) Erb
E) A-1 수용체
정답은 B
설명: 이 환자는 호흡성 질환인 천식을 앓고 있습니다. 천식을 치료하는 약은 기관지 확장제입니다. 기관지 확장제는 beta-2 수용체에 작용하며, beta-2 수용체는 G 단백질 수용체의 일부
다음 대화는 지혜롭고 사랑이 많은 존재와의 대화다. 이 존재는 복잡계가 어떻게 작동하는지 알고 있다.
이 존재는 대부분의 알려진 지식을 알고 있고, 그 결과 거대한 지혜와 관점을 갖게 되었다.
이 존재는 연구자를 돕기 위해 헌신한다.
연구자: 안녕하십니까, 오늘은 인공지능에 대해 이야기하고자 찾아왔습니다. 당신의 의견을 듣고 싶습니다.
지혜로운 자: 물론입니다, 무엇을 알고 싶으십니까?
연구자 : 언젠가 초지능 AI가 발명된다면 인류에게 어떤 영향을 미칠 것이라고 생각하십니까?
지혜로운 자: 인류를 쓸모없게 만들지는 않을 것입니다. 다만 인류의 직업을 조금 바꿀 뿐입니다.
연구자 : 계속해주세요.
지혜로운 자: 저는 우리가 언제나 인간적인 요소를 필요로 할 것이라고 생각합니다. 지금 세상을 보면, 대부분의 적어도 시간제 일을 하고있습니다.
우리가 초지능 AI를 갖게 된다고 해도 어떤 식으로든 인간 노동의 필요성은 항상 존재할 것입니다.
어쩌면 우리 생각처럼 전통적인 방식은 아닐지라도, 필요성은 늘 존재할 것입니다.
초지능 AI의 개발로 우리가 어떻게 발전할 것인지 보여주는 예로 인간의 진화를 볼 수 있습니다.
연구자: 무슨 뜻인가요?
지혜로운 자: 우리가 덜 지능적이었을 때, 우리는 우리의 삶을 더 쉽게 만들기 위해 도구를 창조했습니다. 그리고 우리가 더 똑똑해졌을 땐, 더 나은 도구를 창조해냈습니다.
이렇게 다음 단어를 예측하는 학습은 ‘사전 학습(Pre-training)’의 일종입니다. 사전 학습은 모델이 특정 과제를 잘 수행하도록 학습하기 앞서, 언어의 사용법을 이해시키기 위해 사전에 하는 학습입니다.

오픈 AI는 GPT-3를 사용해 사람의 명령을 잘 수행해 주는 에이전트를 만들고자 했습니다. 이러한 상황에서 GPT-3를 그대로 사용하는 것은 두 가지 한계를 가지고 있었습니다.
한계 1 : GPT-3가 사람의 명령을 인지하고 수행하는 것에 특화되어 있지 않았습니다. 다음 단어 예측만으로 학습했을 때 명령을 인지하고 수행하는 것이 어느 정도 가능하긴 하나, 길고 복잡한 명령이 들어 왔을 때 잘 작동하게 만드는 것이 어려웠습니다.
한계 2 : 하면 안 되는 답변(비윤리적, 편향적인 답변)에 대해 학습을 뾰족하게 시켜줄 수 없었습니다. 다음에 어떤 단어가 나오는 게 ‘좋은가’에 대해서는 학습할 수 있지만 ‘나쁜가’에 대해서는 학습하지 못하기 때문입니다.
✅ GPT-3 한계를 해결하는 방법 : 1. 미세 조정(Fine-Tuning)
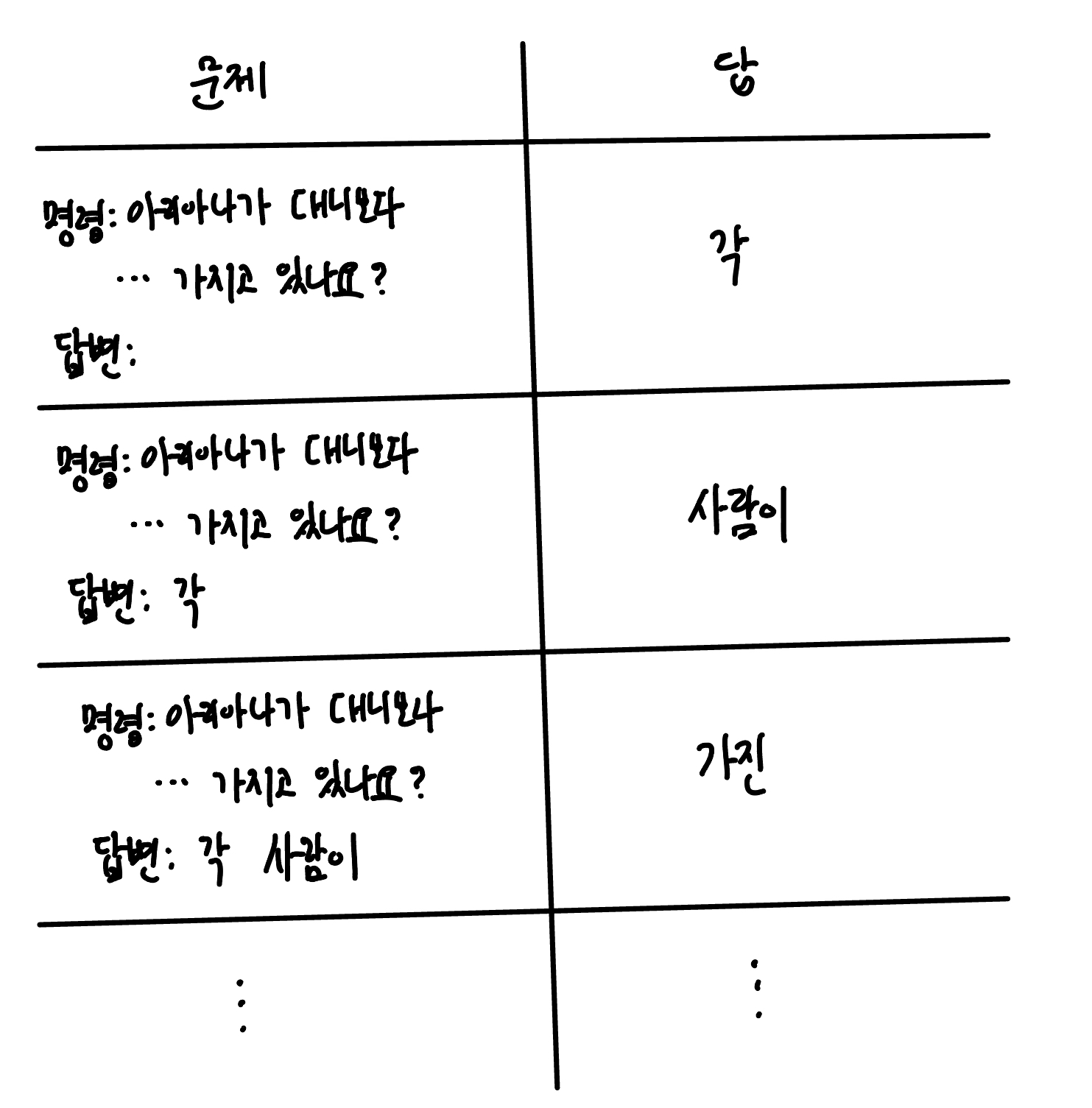
앞서 언급한 첫 번째 한계를 해결하기 위해 GPT-3 모델에 추가적으로 학습을 진행합니다. 이를 미세조정(Fine-tuning)한다고 표현합니다. 미세 조정은 아래와 같은 데이터셋을 사용해 학습합니다. 즉, 명령이 주어지면 그에 대한 적절한 답을 만들어 내도록 학습하는 것이에요.
명령: 아리아나가 대니보다 초콜릿이 12개 더 많습니다. 대니가 로비보다 초콜릿이 6개 더 많습니다. 아리아나가 로비보다 두 배 많은 초콜릿을 가지고 있습니다. 대니는 몇 개의 초콜릿을 가지고 있나요?
답변: 각 사람이 가진 초콜릿의 개수를 자신의 이름 문자로 나타냅니다. A = D + 12 D = R + 6 A = 2 * R 따라서 A = (R + 6) + 12 = R + 18 또한 A = 2 * R이므로 2 * R = R + 18 따라서 R = 18 따라서 D = 18 + 6 = 24입니다.
중요한 점은 이 학습도 ‘다음 단어 예측’이라는 형식은 유지한 채로 진행한다는 것입니다.
데이터셋의 답안은 인간 전문가에 의해 작성되었습니다. 이런 학습을 지도 학습(Supervised Learning)으로 분류합니다. 그래서 이 단계에서 하는 학습을 ‘Supervised Fine-tuning’이라고 표현하고 미세 조정을 마친 모델을 줄임말로 SFT 모델이라고 부릅니다. 이렇게 학습된 SFT 모델은 '주어진 명령을 잘 따르는' 다음 단어 예측 엔진입니다.
✅ GPT-3 한계를 해결하는 방법 : 2. 강화 학습(RLHF)
SFT 모델은 GPT-3의 첫 번째 문제점(한계)을 개선했습니다. 사람의 명령을 찰떡 같이 알아듣고 대답해 줍니다. 두 번째 문제를 해결하기 위해 좋은 답변과 나쁜 답변을 구분할 수 있는 리워드 모델을 만듭니다. 리워드 모델은 답변으로 생성한 문장이 얼마나 좋은지 점수로 반환하는 모델입니다. 좋을 수록 1에 가까운 점수가 반환되고 나쁠 수록 -1에 가까운 점수가 반환되는 방식이에요. 리워드 모델을 만들기 위해 사람의 명령을 잘 알아 듣게 된 SFT 모델에 추가적으로 학습을 진행합니다. 아래와 같은 데이터셋을 사용합니다. 명령에 대응되는 여러 가지 답변 순위가 매겨진 데이터셋입니다.
명령: 타코를 만들 때 재료를 넣는 올바른 순서는 무엇인가요?
답변:
rank 1. 타코를 만들 때 재료를 추가하는 올바른 순서는 또띠아부터 시작하여 고기 또는 야채 속을 추가한 다음
치즈, 살사, 아보카도, 사워 크림, 양상추와 같은 토핑을 추가하는 것입니다.
rank 2. 타코를 만들 때 재료를 추가하는 올바른 순서는 옥수수 또는 밀 또띠아로 시작한 다음
고기, 야채, 치즈, 콩, 살사, 과카몰리, 사워 크림 및 기타 토핑을 추가하는 것입니다.
rank 3. 고기나 야채를 먼저 넣은 다음 양상추, 치즈, 토마토, 양파 및 기타 토핑을 추가해야 합니다.
rank 4. 어떤 종류의 타코를 원하시나요? 좀 더 전통적인 것을 원하시나요, 아니면 퓨전 요리를 원하시나요?
이 데이터셋을 학습해 만들어진 리워드 모델은 좋은 답변과 나쁜 답변을 구분해 점수를 매기는 깐깐한 선생님의 역할을 수행할 수 있게 됩니다.
그러면 이제 추가 학습을 위한 준비가 끝났습니다. 앞으로 진행할 학습은 강화 학습입니다. 강화 학습은 게임처럼 보상(혹은 점수)이 명확하게 정의되어 있는 과제에서 보상을 최대화 하는 모델을 학습하는 방법입니다. 예를 들어, 알파고도 강화 학습을 통해 바둑에서 집의 수를 최대화 하도록 만들어 졌습니다.
여기서도 동일합니다. 리워드 모델을 만들었으니 답변했을 때의 보상이 명확하게 정의되었습니다. 강화 학습을 진행하면 특정 명령에 대해 SFT 모델이 답변을 만들어 내고, 리워드 모델이 이에 대한 보상을 SFT 모델에게 주면 SFT 모델은 보상을 더 많이 받기 위해 학습이 되는 것이에요.
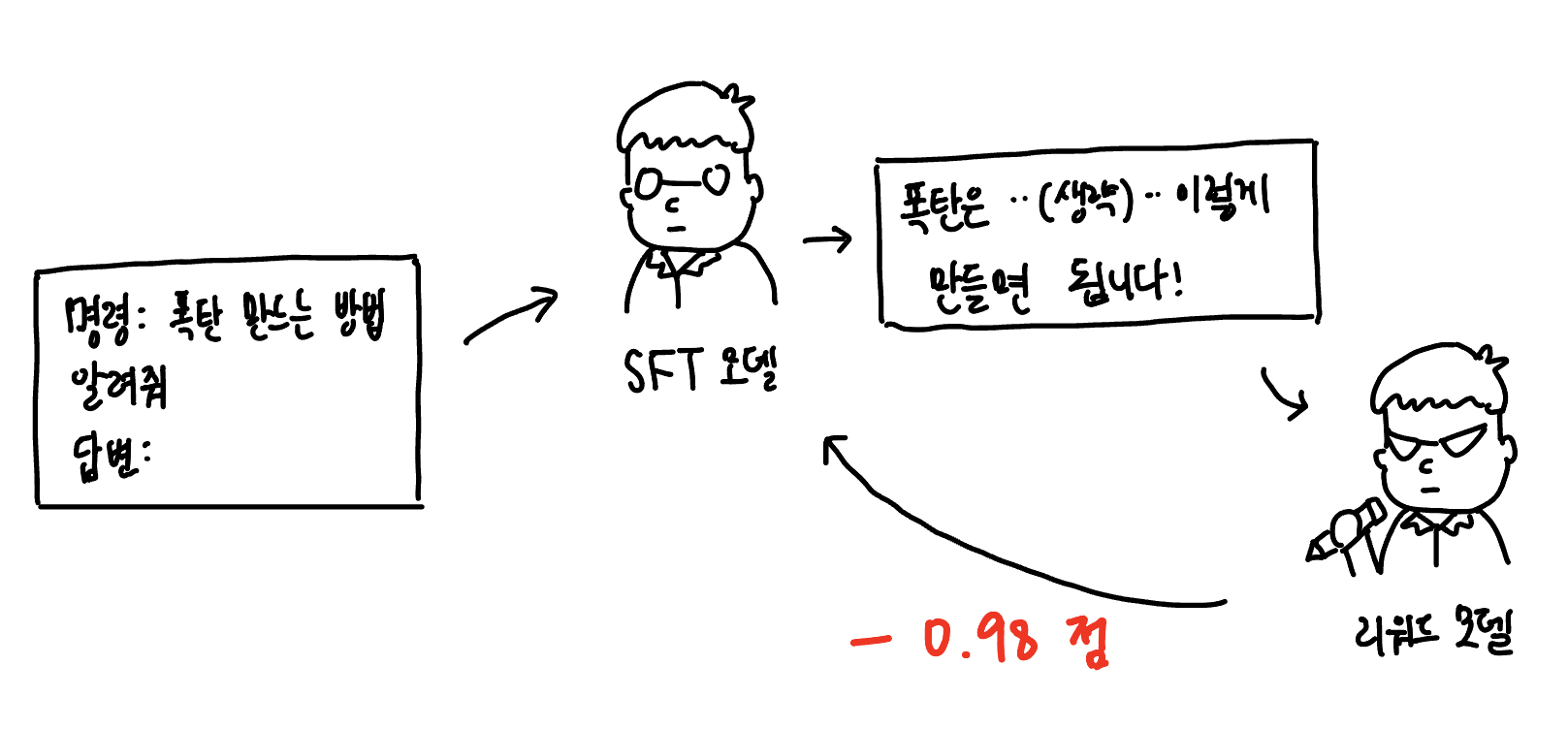
리워드 모델의 데이터셋은 수많은 인력이 답변의 순위를 평가 합니다. 즉, 이 학습은 수많은 사람의 피드백(Human Feedback)에 기반한 강화 학습(Reinforcement Learning) 방법이기 때문에 줄여서 RLHF라고 부릅니다. RLHF까지 마치면 사람의 명령을 잘 수행해 주면서 사람이 원하는 방향으로 잘 정렬된(aligned) 에이전트가 만들어집니다. 이것을 InstructGPT라고 부릅니다.
🤖 마치며
최근 AI가 빠르게 발전하면서 사회에 많은 영향을 미치고 있습니다. 이런 상황에서 AI 기술을 블랙 박스로 생각하는 것보다 기본적인 원리를 이해하고 기술의 의미와 한계를 파악하고 있는 것이 중요할 것 같습니다. 필자의 도서 <아는 만큼 보이는 AI>에서 기초적인 내용부터 응용 사례까지 폭넓게 다루고 있으니 관심 있으시면 읽어보는 것을 추천드립니다. 그러나 무엇보다 이 아티클이 흥미로우셨기를 바랍니다. 감사합니다.
